It has been mentioned before, but not in the request section. The parsing of Chinese subtitles needs a LOT of improvement. It’s almost unusable for saving vocabulary and keeping track of known words or phrases. Many of the characters grouped together as “words” aren’t in any real dictionary (I don’t know what LLN is using as a dictionary, but these words aren’t in any of the many reputable PLECO ones).
Suggestion: Would the technology behind “Zhongwen Chinese Popup Dictionary” extension be useful? It is open source on GitHub. It seems to do a good job parsing and gives the range of shortest and longest viable character chunks that could be considered words or phrases (even some chengyu). You could limit parsing to only to words in the the open source CC-CEDICT dictionary or dictionary of choice.
So depending on which character in a string you click/hover, you will have the option to save and get every definition. For example: 在後面 can be parsed into the words: 在 後 面, 在 後面, or 在後 面. The latter may not make sense in context, but they are real words. If you hover or click on the 後, you should have the option to see and save the definition for both 後 and 後面. If you click on the 在, you should have the option to see and save the definition for 在 and 在後. It will also eliminate a lot of non-sensical groupings that LLR is currently giving. This will cause some color coding conflicts, but that could be resolved by prioritizing certain colors over others where there is overlap and/or by longest dictionary approved character string.
I have been color coding all the words I know and am learning different colors so I can tell at a glance whether I should really work at 100% understanding a sentence or not, or let my brain rest. This inaccurate parsing is definitely a headache. A lot of the “words” aren’t even words. I can’t even save many common words because they are parsed separately or grouped with unrelated characters.
That said, LLR has been invaluable for my learning, so thank you so much for your work so far! It is the only reason I even subscribed to Netflix because of all the soft subs. I just joined the Pro version because color coding what I know, what I’m learning, and what I don’t need to worry about is making a huge difference in learning efficiency. I hope you can make these parsing changes soon to make it even better.
I’m a chinese learner/speaker too, and also want to have a better parsing for chinese (and japanese too btw).
It’s not that trivial and need to focus on the problem for some time, so it’s not in the highest priorities tasks atm, but it will soon come !
PS : For the color cooding for known words, it’s something we are working on actively since some months, so the user will be able to mark his KNOWN and LEARNING words, and we will suggest you new content adapted to the learner vocab level
Will keep you informed for the chinese tokenizer ! Thanks again for the ideas you shared !
I love Language Reactor overall and just bought the three month pro sale so I want to support this project. But when it comes to Chinese learning this is still a huge issue. We really need the option to save ‘custom words’ (character combinations) and not just the automatically parsed semantic blocks.
The underline feature only helps in certain cases, if two characters are perceived as one semantic block there is no way for me to split it up (afaik).
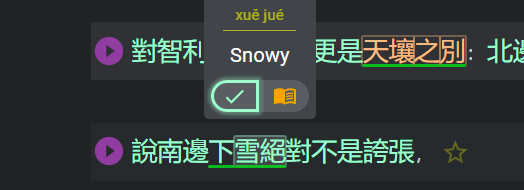
Example: LR parses [雪絕]xue3jue2 as a semantic block. There is no way for the user to save/underline 下雪 xia4xue3 and 絕對 jue2dui4 only.
Please add a feature to user define words in the meanwhile to actually make Chinese learning usable <3
It fails to parse even the most simple sentences correctly, I honestly have a simple error in almost every sentence. I love Language Reactor too and I use it as my primary study method!
I’ve seen this same issue brought up about 2 or 3 years ago, really hope it becomes a much bigger priority for you guys, basically now Chinese learning on there is broken, I hope it can be a priority before all these new features popping up…
I explored LLN in my early Mandarin-learning days a few years ago and have just come back. I think the product per se has improved massively and I congratulate the developers on such an excellent tool.
I was however devastated to see just how not-fit-for-use the Mandarin (traditional characters) mode currently is in so many cases. A random sample of YouTube videos resulted in the vast majority of sentences contained multiple word-parsing errors; far more than when set to simplified characters. I know parsing is non-trivial, and have seen the discussion e.g. here: Chinese Character/Word Segmentation Issues - #8 by quarridors , but that is some years ago now…