Great service! To take it to the next level, I have an idea. Many times, what is being said by the speaker is a “shortened” version b/c native speakers do not always use every word or pronounce every syllable. I wonder if there could be a feature that allows language learners the ability to know that “elision” is or has been used by the person speaking. I imagine that this would be an interesting problem to solve for the ambitious computer programmer.
For background, I am learning Mandarin and have noticed that no matter how slowed down the audio is, the subtitles do not always match what is being said. I am sure that this happens for English language learners as well. For example, they may read the subtitle, “a cup of tea,” but the English language learner hears the actor say “cupatea.”
It’s a good idea, but I think it’s technically difficult to achieve. Possibly with some cutting-edge methods, something could be done, but, it’s unlikely we’ll have time to work on it in the near future. Maybe a specially trained speach recognition system that outputs the phonetic units of a language, rather than usual written forms of words…
For some languages (I’m not sure about Chinese), the problem is that what is written doesn’t always correspond closely to what is spoken (in an extreme case, standard Arabic used in subtitles vs. the dialect which is actually used in the dialogue).
I’ll keep it in mind though and chew on the idea a bit. The best I can suggest is to listen carefully to the audio, try to make sense of it, treating it as the source of truth, and use the subtitles only as a guide to help understanding the audio.
My question is related.
i want to learn Arabic. As a foreign learner , i want to focus on Standard Arabic.
Is there no such Arabic media where what is spoken would be in Standard Arabic to match with the fusha subtitle.
Do we have it in Arabic.
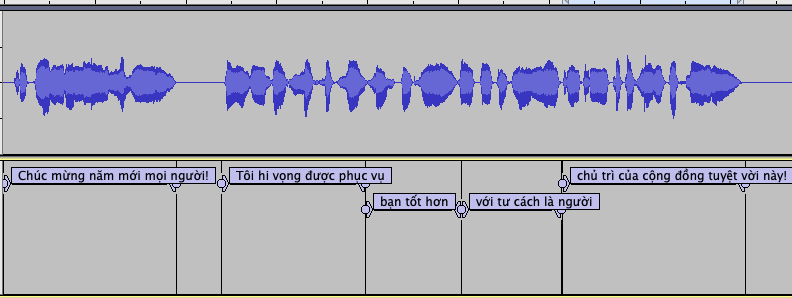
Also, sometimes, these sentences are so long that it’s better to just record the audio in Audacity. I could then chop it into more manageable pieces to really get the pronunciation down. I do this to have better control when I shadow the native speaker for pronunciation practice.
 Maybe a specially trained speach recognition system that outputs the phonetic units of a language, rather than usual written forms of words…
Maybe a specially trained speach recognition system that outputs the phonetic units of a language, rather than usual written forms of words…