We imported many courses (about 100) from https://fsi-languages.yojik.eu/ .
They are accesible (or will be shortly) in the new media catalogue.
About another 8 need further attention before they can be imported:
`yolik_dli-arabic-cope`, // no pdfs
`yolik_dli-arabic-est-asia`, // no audio no pdfs
`yolik_fsi-korean-basic-new`, // just one brief pdf
`yolik_dli-korean`, // Integrated Korean, no pdfs
`yolik_dli-serbian`,
`yolik_dli-serbian-solt-complete`,
`yolik_dli-thai-complete`, // lots of tidy
`yolik_dli-chinese-mandarin-refresher`, // no pdf, jpegs etc.
The Cortina courses have not been imported as we didn’t request permission to do so yet.
Courses that don’t have some level of NLP support in Language Reactor where not imported.
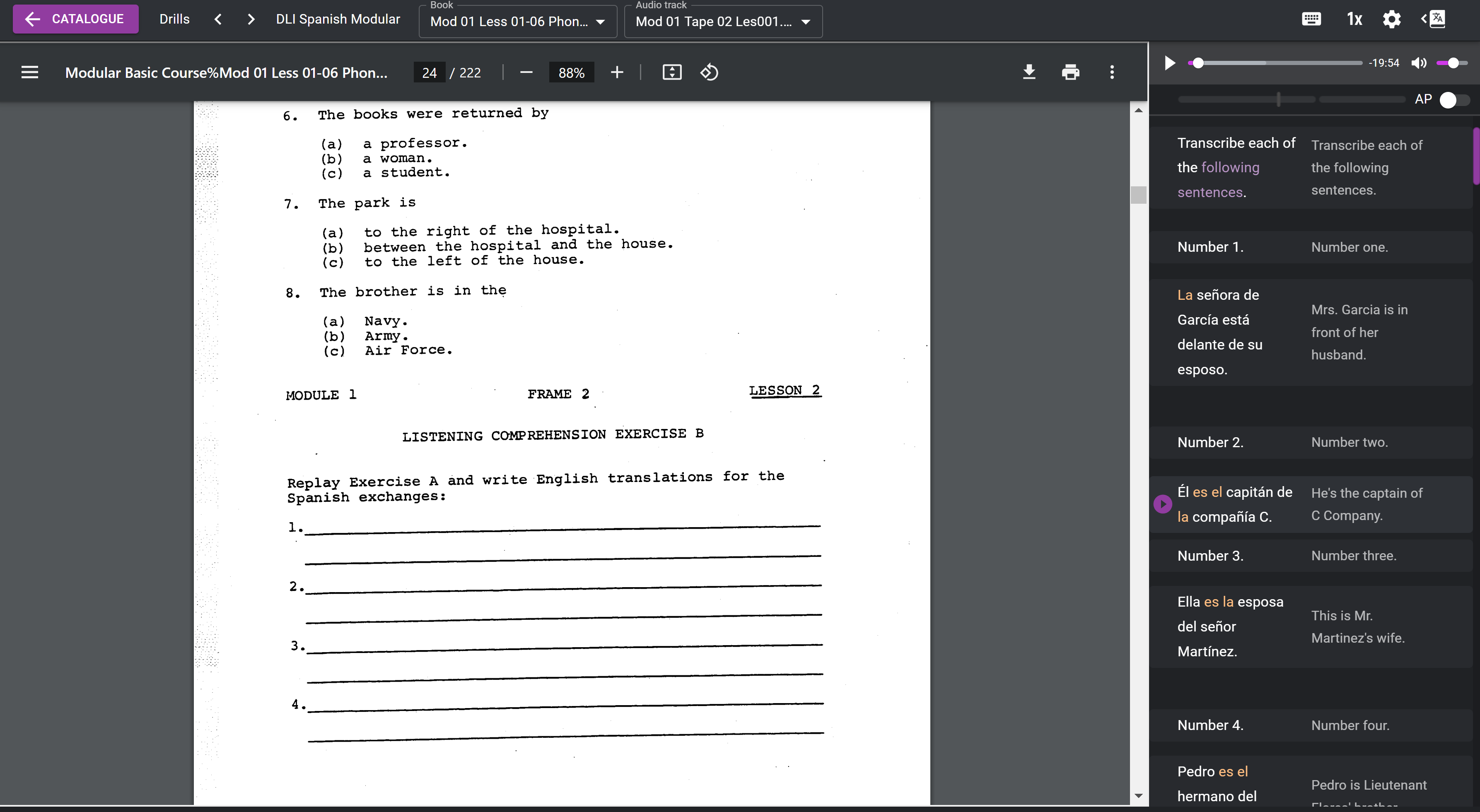
The approach we went for (initially) was to present the books and audio in the original format, without OCR/transcribing the books… the volume of material is vast.
Notes:
– Select the Book and Audio tape from the dropdowns at the top.
– Use ‘A’ ‘S’ ‘D’ keys to move to the next audio prompt, left/right arrows to jump back/forward 5 seconds.
– The audio transcription isn’t perfect, I will take another look soon. Translations, dictionary, word saving works as expected.
– There is some really useful material here, it’s worth to have a good dig. I am a fan of pattern drills for building speaking ability. You still need to speak with people, else you might end up being able to ‘talk’ in your language, but not able to converse. A funny problem to have.
Current known issues:
– Speech recognition not working exactly as hoped, some speech segments are not recognised or have poor timing.
– Image-based PDFs are a bit heavy and cumbersome in the browser, processing them to optimise them can help.
This thread is for discussion for comments and issues relating to how they are presented in Language Reactor.
I may set up a seperate forum for Eric to assist with further collecting and digitalisation of these courses.
More information to follow. ![]()