So a feature that takes the sound of the characters and translates that sound into subtitles. Then, it would do a literal word for word translation to get the user used to the word orders and grammar used in that language.
So
Encantado
de
conocerte
Becomes literally something like:
Charmed
from
meet
Or even something that just does a word for word translation of the existing subtitles without bothering with audio->voice first?
Purpose: to help someone get used to the word order that people in a language use, to help learn vocabulary faster
Even though it would look a bit weird to see literal word for word translations, I still think it would be worth it to have this option.
This would just be a supplement to the existing modes, not a replacement.
I’m fully aware one can pause the video and look up the individual words but that is not what this thread is about. I’m aware a word for word translation does not always work, but it does help a total beginner get started on a new sentence to know roughly what each word means and their order.
It would be great if this feature would also visually align the words so the user can immediately see which word is which
Hello. It’s a good idea… actually we can enable highlighting, where you hover on a word in the subtitles, and the corresponding words in the translation are highlighted. The problem is we only have this alignment data for about 15% or so of our translations. We could try generating the other alignments ourselves (there’s a tool called GIZA++, it might be suitable). If we reorder the word-order of the translation to match the source subtitles… interesting idea, would need to try it and see, I guess.
The limitation we have is that there’s only two of us… I always have to decide between spending time developing a new feature, fixing bugs (there’s always some issues), or replying to the backlog of emails (I try to respond within a week or so currently). Currently we are spending time on youtube support, and a mobile app for flashcards (there’s Anki export, but not everything we wanted to do is possible with Anki).
For the next update, maybe we can enable word highlighting for the 15% of data we have… further experimentation (GIZA++) probably will have to wait a couple of months or so. Thanks for writing.
EDIT: there’s some information about the technical approach on wiki: https://en.wikipedia.org/wiki/Bitext_word_alignment (mentions GIZA++). If there’s any NLP researchers reading this with a specific recommnedation, happy to hear from you.
Anki is infinitely powerful and pretty much the standard. Could you make the Anki export feature a little bit smoother and more powerful? Things that come to mind:
Individual columns for show title, season, episode, episode title, subtitle time code
Each individual column can be enabled/disabled in the export window
Why does the export file have html in it? I currently have a lot of cleaning up to do before I can import
God feature: Take screenshot of current scene when subtitle shows, to give more context when SRSing
We can probably do better even, and send the audio clip from the original movie. It’s on the todo list.
We were also investigating syncing directly to AnkiWeb, but, it would have needed quite some work (and I’m not sure Damien is a fan of the idea). I also looked in detail into doing .apkg export from LLN. The export/import process is a bit clumsy and is the main issue with Anki imo.
Having Anki export include the audio clip and a screenshot would be an amazing feature!
I didn’t spend much time trying out the Anki export, but I found I was doing a lot of copy-pasting to reformat the cards because I wanted the title, episode and original subtitle on the front and both the human and machine translations on the back of each card.
That didn’t seem to be something the system could do at the moment, but I didn’t investigate much further because I quickly realised the export wouldn’t be very useful without audio clips included.
I had begun investigating solutions like http://subs2srs.sourceforge.net/ but obviously they’re not suitable for Netlfix content.
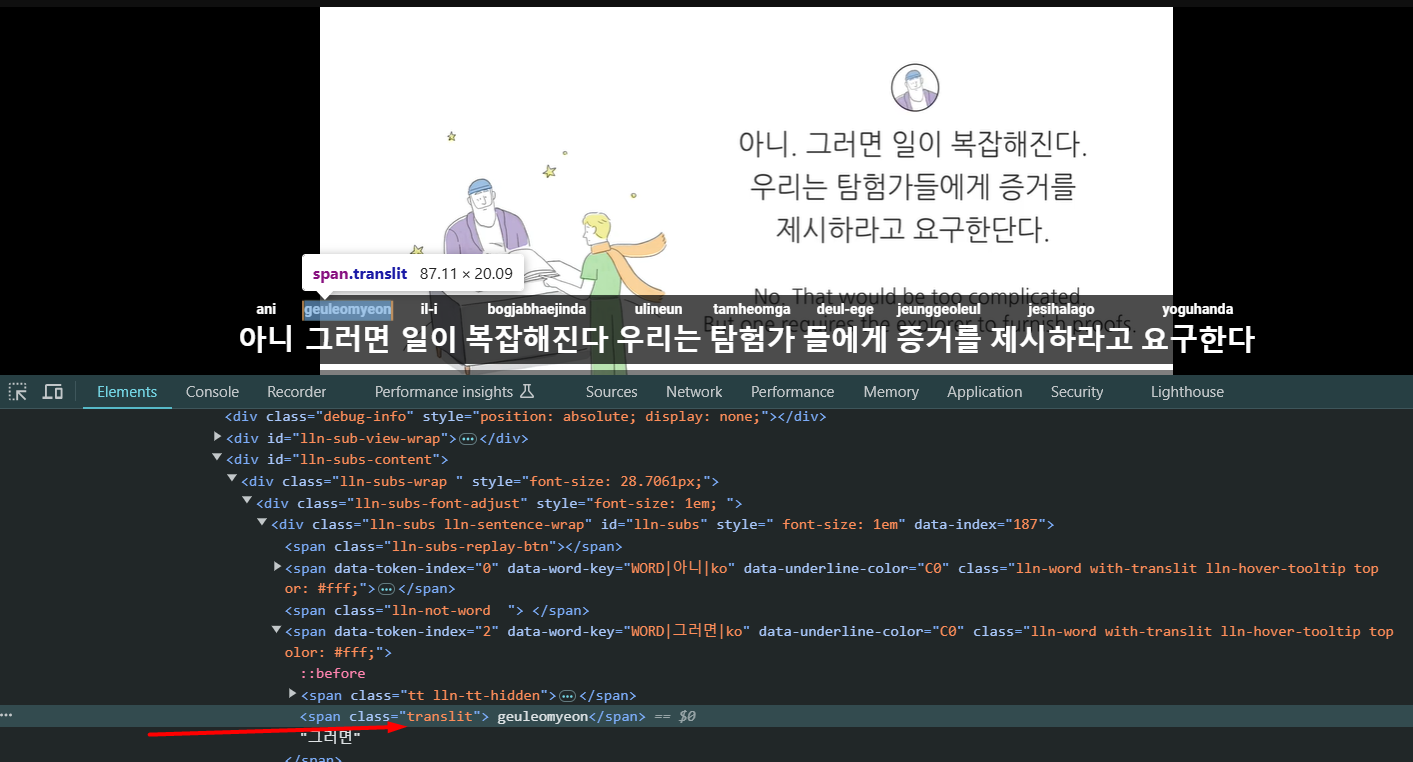
I think we have class “translit”, if it’s possible just to give option to insert translation for each word there, it would be super nice. I’m trying to learn Korean, but in Korean, the typical word order is subject-object-verb (SOV), as opposed to English’s subject-verb-object (SVO) order. It creates of lot of confusion for newbies.
Btw, there is no extension or app with such functionality with translation word by word for now. I searched all day, and couldn’t find.
I even created the Tampermonkey script to take translation from class “tt” and inject it in the class “translit”. But it doesn’t work for now very well, as translation for each word works through async request. Maybe I can hover everything using Tampermonkey script to receive all words every time, but I don’t want to make such big number of requests. Or I even thought to install local API translation server, make request using Tampermonkey to substitute class “translit”.