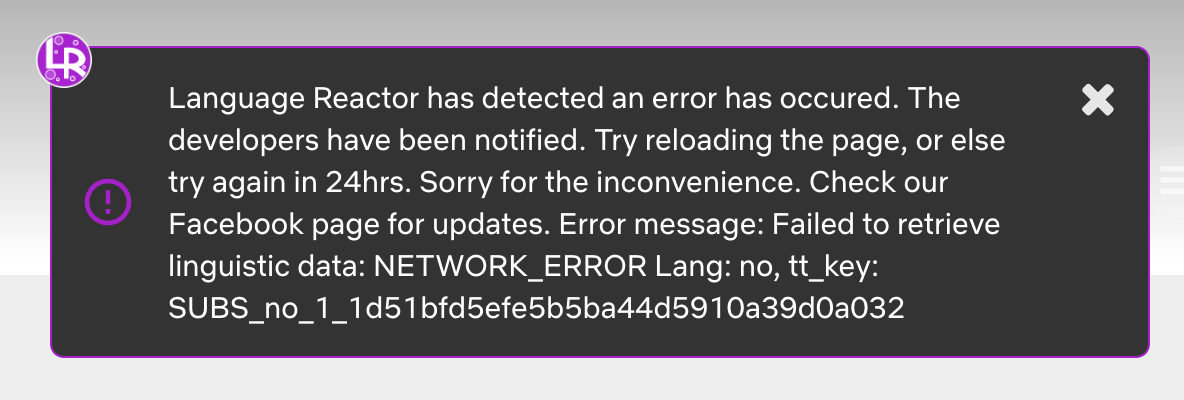
It’s glitching again. Any quick fixes?
Hard disk full on NLP server… probably logs are filling up the drive… routing to secondary server… 2 mins.
I understand your problem. Me and Og just talked about this it for a couple of hours. I think we have a nice way to solve the problem. Give us a couple of days to work out a couple of details and implement, I think you will be happy. ![]()
2 Likes
When we made the update, we switched over to different servers with the new code, these were accessed using a different ‘port’ (something like an extension number, when you make a phone call). It’s possible your ISP… or a firewall in your hotel, office etc. didn’t like this non-standard port (2000), and blocked it. Anyway, I switched it back to use only standard, vanilla ports (443).
tldr: try it again, hopefully it works now. ![]()
It works now (I am the guy who wanted to watch the Korean shows). Thank you so much, SO MUCH!! I love your extension, it is so awesome, it taught me most of the Korean I know. Thank you thank yuo
2 Likes
I’m going to bed, Ognjen is putting an update online in a few hours. The changes are:
– White is used as the ‘Known’ colour, rather than green (bit less intense).
– You can turn off colouring of ‘Recommended to Learn’ words, and ‘Marked to Learn’ remain orange. It’s nice if you aren’t interested in recommendations and just want to see what you saved.
– The settings around these features have been simplified slightly, and some UI tweaks to help make things more understandable.
gnight.
2 Likes
I truly need the ability to highlight actual individual words and I would like to choose which words or sentences I could practice or review in Phrasepump.
When I started using Learning with Netflix, I just marked the words I didn’t know. Although, I was slowly learning new words, it was just really difficult to understand subtitles in Chinese.
Then I deleted all my highlighted words and took a different approach. For a short period of time, I only highlighted introductory phrases, adverbs and the grammar constructions that was learning in yellow. This was wonderful because it was easier to chunk and understand the subtitles.
So, the characters 了,在,被 are always marked as yellow. Not because I don’t know them, but because they help emphasize other words in sentences and chunk the sentences into smaller parts. Marking the names in red also helped me parse the sentences correctly. When you don’t know many words in Chinese, you don’t know where one word ends and another begins. Highlighting the characters really helped with this. The underlined tags just aren’t as efficient.
When you introduced the word counts, I slowly moved from 1000 to 6000 before the update. This was perfect for me. Even when I was lazy and didn’t want to mark a bunch of nouns and verbs that I didn’t know the purple, grey, and white settings automatically helped break up the sentences even more. I didn’t need to mark every word. I only marked the words that prevented understanding. Every time I moved up a level, I deleted all highlights and started from scratch.
Soon I was watching native tv shows and making real progress. I was also able to easily change the highlights according to the series I was watching. Right now I am watching a show about chess. Chess terms aren’t highly used in real life, but it would be great if those specialized terms could be used in Phrasepump. Right now it only wants to test me on 了 and 在。Or it wants to test me on 等 meaning to wait. Literally, one of the first words I learned. I have highlighted 等 to draw attention to how it is used meaning after, as soon as, or once.
等 等 děng class; rank; grade; equal to; same as; to wait for; to await; et cetera; and so on; et al. (and other authors); after; as soon as; once
Thanks for all your hard work because I will always appreciate the progress I made with the previous version. But the new update has changed the focus from customized subtitles to Phrasepump. I like the idea of Phrasepump. The voice for Chinese sounds great, but I need Language Reactor to allow me to control some of the highlighting features. It feels like I have lost control and now everything is automated.
Please note that I have tried switching each feature on and off. I currently have all colors OFF, highlight box ON, tabs ON. For me all words in white is better. Now I can’t turn the orange words off even though I have changed the settings.
Highlighting the subtitles was a unique feature that allowed me to create my own visual system in order to better understand Chinese subtitles in real time or in stop pause. Highlighting helped when words were not parsed correctly in Chinese, the font was hard to read, and when words had multiple meanings. The customization was the key.
Please consider what I have said. I know it isn’t easy to meet the needs of a large group of people. Sorry for the long post.
Best wishes
I concur with @sassysocks . I might have been a tad harsh in my previous comment, and i still believe LR is a great tool for learning languages, but this update really is, in some regards, a step back.
As of right now, picking a vocabulary level blanket assigns every word within the relevant frequency list the ‘known’ attribute. It should be obvious that a person’s vocabulary doesn’t surgically stop at a specific word frequency count. For learners; the words are scattered throughout the frequency counts (where the density of ‘known’ words is greater the higher frequency categories).
It would be a welcome option to disable blanket-assigning the ‘known’ attribute by all words in a give frequency list when picking one, because right now i have to do that manually (which is a chore). It would also be a welcome addition to customize the frequency count, instead of having to choose from pre-selected options. It would also be useful to customize the amount of words to be assigned the ‘learned’ attribute. Right now, if i were to guess, it seems to be 300-500 words on top of the current known vocabulary, and sadly this is immutable.
Second, as Sassysocks mentioned, custom highlighting seems to have been removed altogether. And my question would be: why?. I can’t think of any reason why this was implemented. You state that you personally prefer to assign the colour white to ‘known’ words. Why not simply make it customizeable to the user (as it was before the update)? I also assigned different highlighting colours for my own purposes, and now they are replaced by underlines which are significantly harder to notice.
EDIT: Typically i use the LR tool outside its own domain (on Youtube). I noticed that on LR’s own demain, ‘known’ and tagged words do still show up green. Not that i am complaining (i do prefer it that way), but there seems to be a disconnect.
1 Like
I’m confused: it seems as though now the “known” colour is white, as well as the unmarked words. This is really confusing for me. I want the known colour to be maybe grey and then the unmarked words to be white (so that I can spot them and easily mark them for either to learn/learned)
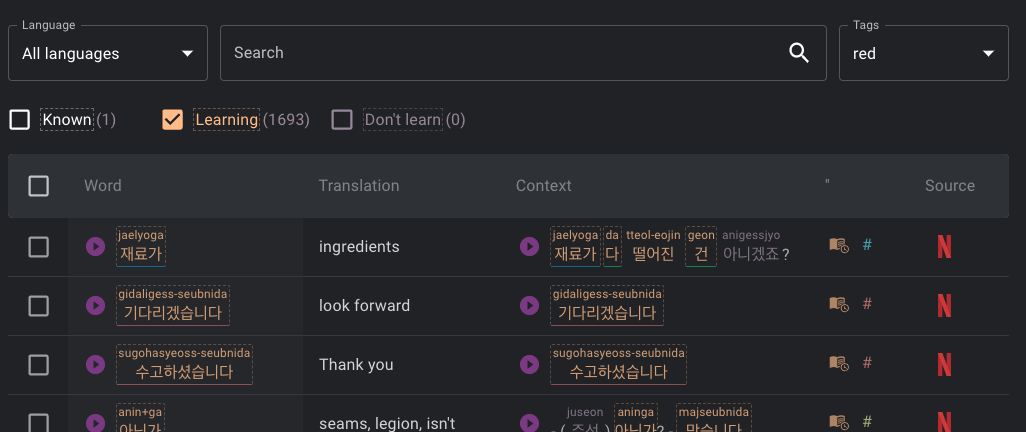
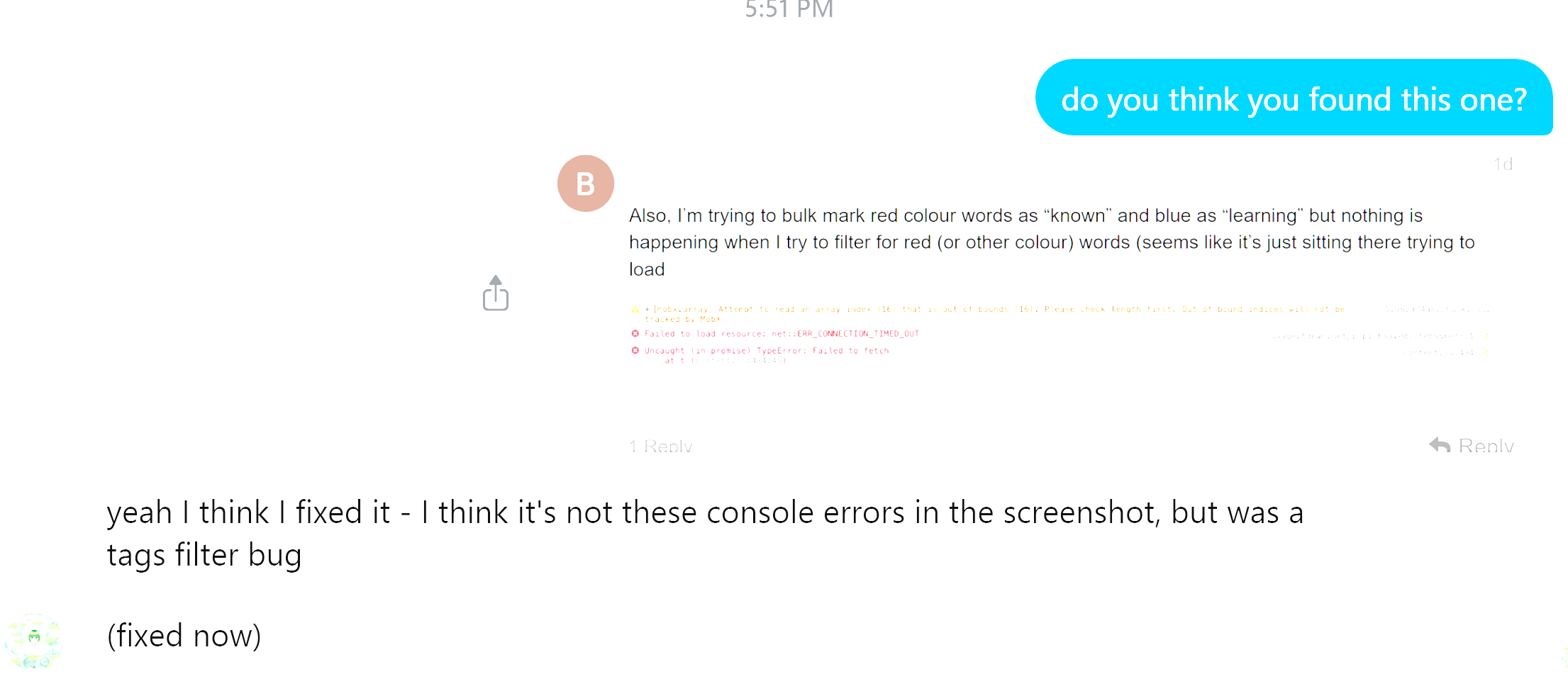
Also, I’m trying to bulk mark red colour words as “known” and blue as “learning” but nothing is happening when I try to filter for red (or other colour) words (seems like it’s just sitting there trying to load

Here is what is supposed to be only red-underlined words but as you can see, all words are showing up
Your feedback is valuable. The current system should give you complete control over what you see in Phrasepump. You might need to change the default options.
When you don’t know many words in Chinese, you don’t know where one word ends and another begins.
One idea was if users switch their items to ‘Learning Stages’ (Known/Learning), they could use underlines for showing gramatical annotation… such as cases for slavic languages… gramatical gender… or I guess for Chinese, we could give an alternating colour underline to show where words start/end. We could also insert a gap or a symbol between words. It’s quite easy to add. One note: word segmentation in Chinese is not perfect at the moment, we’re using the best library (pkuseg) for Simplified, but our attempt to upgrade Traditional hit a snag, still using ‘jieba’ for that.
coloured underlines:
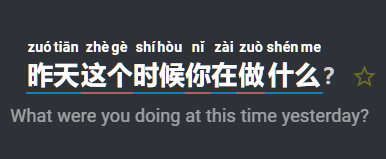
with extra spacing:
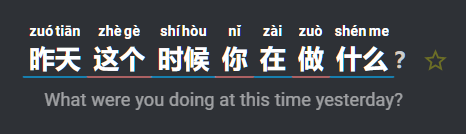
Every time I moved up a level, I deleted all highlights and started from scratch.
As you mark words as know now, the greyed-out words will also adjust. The logic isn’t quite battle tested yet, but it’s operational.
Chess terms aren’t highly used in real life, but it would be great if those specialized terms could be used in Phrasepump.
It should totally work. The way PhrasePump selects new words to add to the study pool: first it takes words you marked to study (orange with dash), then, if ‘Suggestions’ are enabled in PhrasePump settings, it takes the lowest frequency word that is not marked as Known. This logic should be made more explicit. So, turn off ‘Suggestions’, and mark the chess words, they should appear in PhrasePump. The pool of Chinese sentences is not so rich as other languages, but should be sufficient to provide varied examples for words up to about rank 5000. For other major languages it works to 15k or even 20k+.
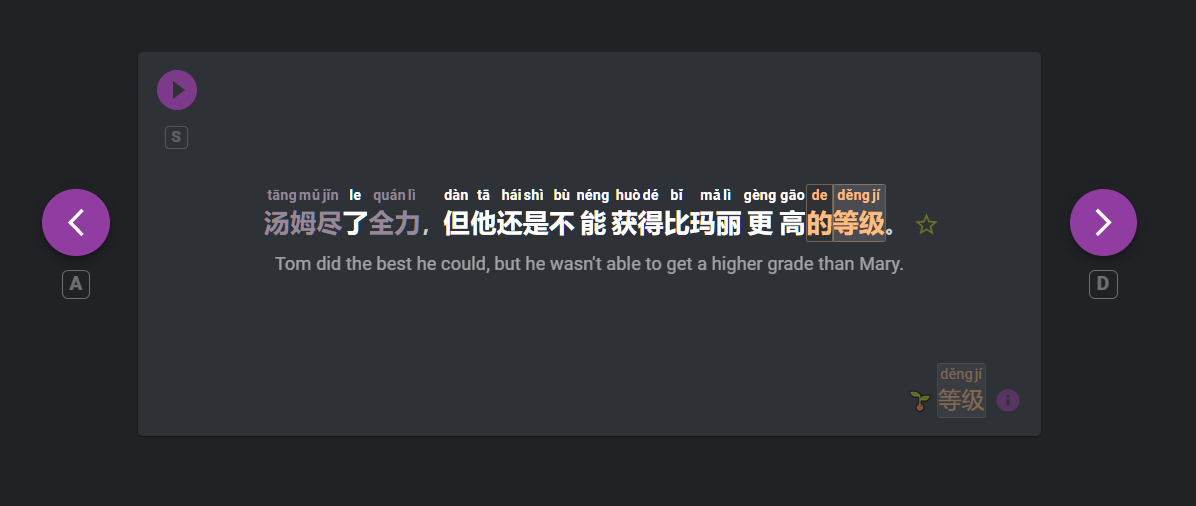
‘Tom’ is showing as grey here, it was intended to be white, need to check that.
I have highlighted 等 to draw attention to how it is used meaning after, as soon as, or once.
With the current system, these should probably set as tags, with ‘Learning Stage’ - ‘Known’. I know it’s not quite as visible, but I’m hoping you like one the suggestions I had to display word segmentation.
Now I can’t turn the orange words off even though I have changed the settings.
Words that have been manually marked as ‘Learning’ are always in orange at the moment.
1 Like
I know the last year it probably came across as if we lost interest in LR. It’s only me, Og and Hofit. The code is growing daily and attention is split between prototyping, implementing new features, code maintence, hardware maintence, communicating with users, and more stuffs. Simply not enough butter to butter everything. This update was (is) particulary tricky, with disagrements within the group. I think we’ve nearly got it now. Stability should improve and new features should be faster now.
…a person’s vocabulary doesn’t surgically stop at a specific word frequency count… It would be a welcome option to disable blanket-assigning the ‘known’ attribute by all words in a give frequency list when picking one, because right now i have to do that manually (which is a chore).
Blanket-assigning, I call it, ‘bulk-marked’ ![]() Bulk-marking is meant to give you a starting point, then you can go in and mark individual words. Bulk-marking doesn’t change the status (or colouring) of anything that has been manually marked (words with dashes around them in the SAVED ITEMS - ALL WORDS tab on the LR homepage). You can set it up to the maximum level, then drop it right down, it’s reverseable, nothing is lost. That’s what the dashes are about, to show a distinction between ‘bulk marked’ and manually marked words.
Bulk-marking is meant to give you a starting point, then you can go in and mark individual words. Bulk-marking doesn’t change the status (or colouring) of anything that has been manually marked (words with dashes around them in the SAVED ITEMS - ALL WORDS tab on the LR homepage). You can set it up to the maximum level, then drop it right down, it’s reverseable, nothing is lost. That’s what the dashes are about, to show a distinction between ‘bulk marked’ and manually marked words.
I know it’s quite a complex interface.
Phrase pump ‘Suggestions’ are also a way the software can ask you about your knowledge of a word, progressively, as that information is needed (the buttons at the bottom allow you to set the learning stage). It only asks you about a few words per session, which you might already know… in which case, ideally, it would carry on suggesting more. That didn’t make it into this release. If you marked everything ‘known’, close the session at the end of the suggestions, and start a new one. You’ll get a fresh set.
It would also be a welcome addition to customize the frequency count, instead of having to choose from pre-selected options.
I was bugging Og to make the level setable to within 100 words. Thanks for the ammunition. ![]()
I also assigned different highlighting colours for my own purposes.
If it makes sense for your use case, I suggest to bulk-move tags over to ‘Learning Stages’, so you restore word-colouring.
It would also be useful to customize the amount of words to be assigned the ‘learned’ attribute. Right now, if i were to guess, it seems to be 300-500 words on top of the current known vocabulary, and sadly this is immutable.
Without looking at the code, it’s 1.75 * (number of known words + number of words in the study pool) + 100. Yeah, the 1.75 needs a slider in the settings, we’ll get to it.
custom highlighting seems to have been removed altogether
Before, you right clicked on stuff, and it cycled between two colours and white. Now, you right click on stuff, it cycles between orange and white, but these colours have meaning attached to them that allow us to develop the frequency-based features. If you were using the four colours, or, for some users like sassysocks that were using the colours for a specific purpose, we’ve created a problem for you. But, let’s see if we can address the problems. Allowing customisation of the colours, it is simple enough. We’ll get it shortly. I can tell you, people can have very strong feelings about their colour preferences.
I noticed that on LR’s own demain, ‘known’ and tagged words do still show up green.
Did you refresh the window? I have a suspicion that new code isn’t reaching users as fast as it should. It’s a bit worrying.
Summary of changes to make (as I understood):
– level setable to within 100 words
– setting to adjust ratio of ‘suggested’ (currently 1.75) and ‘rare words’
– customisation the colours used for ‘Learning Stages’
1 Like
Og checking it out now.
Okay, so I realized it was because I had set my vocabulary level, so it was assuming I knew some words that I didn’t actually no. Once I set my level to 0 it worked that the only words in white were the ones I’d assigned as “known.” However, I do think it’s more intuitive if the known words are in the dark grey and unassigned words are in white, as the white stands out more. Or better yet, let the user decide which colours to assign for what (doesn’t need to be a big colour palette). Thanks!
1 Like
Thanks for your quick response. I’m going to think about what you have suggested.
My initial reaction:
“The current system should give you complete control over what you see in Phrasepump.”
My concern is not how the sentences look in PhrasePump, but in Netflix or YouTube when I am watching a show at real speed. The extra seconds that are needed to try and discern the underlined tags are the difference between understanding and eye strain. The colored character is so much better. Just one color I could control would better.
Segmentation:
Honestly, I do not want to see any alternating underlines or additional spaces. Real Chinese books and shows don’t have this kind of spacing. I know the segmentation is not perfect, but I’m not complaining. Please do not add additional spaces between the words or alternating underlines UNLESS these features are OPTIONAL and could be turned ON/OFF by the users.
Known words:
It seems you are suggesting I move a lot of words to known. I will play around in the settings, but everything I have tagged YBRG is now orange. Before I only needed to mark the color. Now I need to adjust two settings for most words.
Color: green, white, and orange
For me, the orange is still a bit much. When the words are orange, I can’t see the tags.

Maybe you could allow users to choose which color is learned, known, and ignored or allow users to change the intensity of the colors.

I would make KNOWN words grey, LEARNING white, and IGNORED orange. I’m assuming that most of the words I am going to see in the average tv show are known. That said, I would have to manually mark the words I really want to ignore as known. Then I could reserve the orange for special items I really want to stand out. For example:
了,在, and grammar constructions. These words wouldn’t be in PhrasePump, but I would be able to clearly see them and change them at will. I hope this makes sense.
Customization and simplicity are key.
Thanks for your time.
I can’t seem to log in post most recent update. It just times out.
Thanks for your efforts, it’s a great thing.
Since the first moment I made (known words) white ![]() , it is better to get less colors.
, it is better to get less colors.
But still the grey colour is difficult to see especially with grey background, if you try to make it darker it would be a generous gesture from you.
My hat is off to you